DCGAN学习笔记
1. 什么是GAN(Generative Adversarial Net)?
假设有一个警察和一个造假币者,造假者按照真实钱币的样子来造假,警察来分辨遇到的钱币是真还是假。最初的时候,造假者的造假能力不高,所以警察可以很容易的分辨出来。当被识别出来的时候,造假者就会继续修炼自己的技艺。与此同时,警察的分辨能力也要相应提高。这样的过程就是一种生成对抗的过程。对抗到最后,造假者已经能够创造出可以以假乱真的钱币,警察难以区分真假。所以猜对的概率变成0.5
来源:知乎
1.1 生成模型(Generator)
生成模型G的输入是随机噪声Z。
1.2 判别模型(Discriminator)
判别模型D输入x,输出0-1范围内的一个实数,用来判断这个图片是真实图 片的概率有多大,相当于一个二分类器。
1.3 工作原理
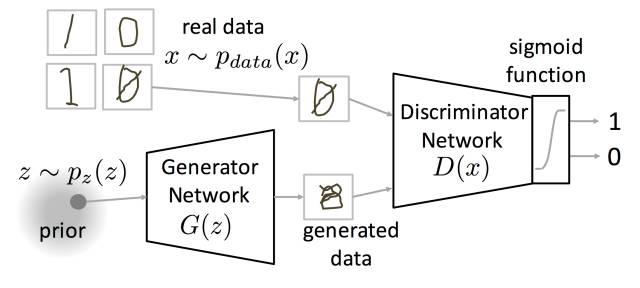
X是真实数据,真实数据符合Pdata(x)分布。z是噪声数据,噪声数据符合Pz(z)分布,比如高斯分布或者均匀分布。然后从噪声z进行抽样,通过G之后生成数据x=G(z)。然后真实数据与生成数据一起送入分类器D,后面接一个sigmoid函数,输出判定类别。
1.4 GAN目标优化函数
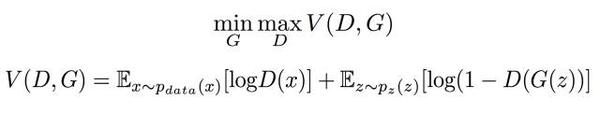
固定G训练D时:
![img]()
D是判断模型,真实的数据希望被D分成1,生成的数据希望被D分成0。
第一项表示真实数据,如果错认成了0,那么log(D(x))<<0,期望会变成负无穷大
第二项表示生成数据,如果错认成了1,那么log(D(x))<<0,期望会变成负无穷大
从而修正参数,使得V大起来,所以训练D的目的是希望这个式子的值越大越好
固定D训练G时:
G是生成模型,希望D判断G生成的数据为1
目标函数第一项不包含G,是常数,直接忽略。
第二项只有当D为1时,V是最小的,所以训练G的目的是希望这个式子的值越小越好
![img]()
第二个式子和第一个式子等价。在训练的时候,第二个式子训练效果比较好 常用第二个式子的形式。
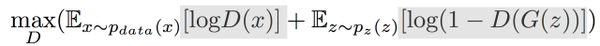

1.5 描述
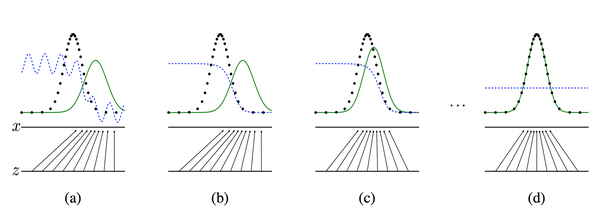
第一个图是一开始的情况,黑色的线表示数据x的实际分布,绿色的线表示数据的生成分布,我们希望绿色的线能够趋近于黑色的线,也就是让生成的数据分布与实际分布相同。然后蓝色的线表示生成的数据x对应于D的分布。在a图中,D还刚开始训练,本身分类的能力还有限,因此有波动,但是初步区分实际数据和生成数据还是可以的。到b图,D训练得比较好了,可以很明显的区分出生成数据,大家可以看到,随着绿色的线与黑色的线的偏移,蓝色的线下降了,也就是生成数据的概率下降了。那么,由于绿色的线的目标是提升概率,因此就会往蓝色线高的方向移动,也就是c图。那么随着训练的持续,由于G网络的提升,G也反过来影响D的分布。
2. 什么是DCGAN(Deep Convolutional GAN)?
2.1 DCGAN对GAN的改造
- 去掉了G网络和D网络中的pooling layer
- 在G网络和D网络中都使用Batch Normalization
- 去掉全连接的隐藏层
- 在G网络中除最后一层使用RELU,最后一层使用Tanh
- 在D网络中每一层使用LeakyRELU。
ps:要这样做只是因为看起来效果好。就是纯粹工程调出来了一个不错的效果。
2.2 一些约定俗成的规矩
- 在Discriminator和generator中大部分层都使用batch normalization,而在最后一层时通常不会使用batch normalizaiton,目的 是为了保证模型能够学习到数据的正确的均值和方差
- 因为会从random的分布生成图像,所以一般做需要增大图像的空间维度时如77->1414, 一般会使用strdie为2的deconv(transposed convolution)
- 通常在DCGAN中会使用Adam优化算法而不是SGD。
3. 用pytorch实现DCGAN
计算尺寸大小的公式:H_out=(H_in-1)*stride-2*padding+kernel_size
3.1 生成器定义
1 | class NetG(nn.Module): |
直接使用·nn.Sequential 将上卷积、激活、池化等操作拼接起来即可,这里需要注意上卷积 ConvTransposed2d 的使用。当 kernel size 为 4、stride 为 2、padding 为 1 时,根据公式 H_out=(H_in-1)*stride-2*padding+kernel_size,输出尺寸刚好变成输入的两倍。最后一层采用 kernel size 为 5、stride 为 3、padding 为 1,是为了将 32×32 上采样到 96×96,这是本例中图片的尺寸,与论文中 64×64 的尺寸不一样。最后一层用 Tanh 将输出图片的像素归一化至 -11,如果希望归一化至 01,则需使用 Sigmoid。
3.2 判别器的定义
1 | # 定义鉴别器网络D |
可以看出判别器和生成器的网络结构几乎是对称的,从卷积核大小到 padding、stride 等设置,几乎一模一样。例如生成器的最后一个卷积层的尺度是(5,3,1),判别器的第一个卷积层的尺度也是(5,3,1)。另外,这里需要注意的是生成器的激活函数用的是 ReLU,而判别器使用的是 LeakyReLU,二者并无本质区别,这里的选择更多是经验总结。每一个样本经过判别器后,输出一个 0~1 的数,表示这个样本是真图片的概率。
3.3 训练模型
1 | import argparse |
(1)训练判别器。
- 固定生成器
- 对于真图片,判别器的输出概率值尽可能接近 1
- 对于生成器生成的假图片,判别器尽可能输出 0
(2)训练生成器。
- 固定判别器
- 生成器生成图片,尽可能让判别器输出 1
(3)返回第一步,循环交替训练
3.4 实验结果分析


